






 BTC/HKD+0.45%
BTC/HKD+0.45% ETH/HKD+0.03%
ETH/HKD+0.03% LTC/HKD+0.04%
LTC/HKD+0.04% DOT/HKD+1.95%
DOT/HKD+1.95% ADA/HKD+0.48%
ADA/HKD+0.48% SOL/HKD+1.41%
SOL/HKD+1.41% XRP/HKD-0.18%
XRP/HKD-0.18% DOGE/US+1.18%
DOGE/US+1.18%ChatGPT是個啥?
近期,OpenAI發布了ChatGPT,是一個可以對話的方式進行交互的模型,因為它的智能化,得到了很多用戶的歡迎。ChatGPT也是OpenAI之前發布的InstructGPT的親戚,ChatGPT模型的訓練是使用RLHF也許ChatGPT的到來,也是OpenAI的GPT-4正式推出之前的序章。
什么是GPT?從GPT-1到GPT-3
GenerativePre-trainedTransformer(GPT),是一種基于互聯網可用數據訓練的文本生成深度學習模型。它用于問答、文本摘要生成、機器翻譯、分類、代碼生成和對話AI。
2018年,GPT-1誕生,這一年也是NLP的預訓練模型元年。性能方面,GPT-1有著一定的泛化能力,能夠用于和監督任務無關的NLP任務中。其常用任務包括:
自然語言推理:判斷兩個句子的關系問答與常識推理:輸入文章及若干答案,輸出答案的準確率語義相似度識別:判斷兩個句子語義是否相關分類:判斷輸入文本是指定的哪個類別雖然GPT-1在未經調試的任務上有一些效果,但其泛化能力遠低于經過微調的有監督任務,因此GPT-1只能算得上一個還算不錯的語言理解工具而非對話式AI。
Mike Novogratz:機構投資者購買放緩導致了加密市場近期的低落:金色財經報道,Galaxy Digital 首席執行官Mike Novogratz在 6 月 1 日接受CNBC采訪時表示,雖然相對較小的散戶買家以其適度的持有量為市場增添了一些穩定性,但缺乏大型買家正成為一個問題。但Novogratz指出亞洲的兩個重大發展可能有助于扭轉這一趨勢。
首先,中國社交媒體微信現在提供比特幣的報價,鑒于其受歡迎程度,他認為這是一個重要的里程碑。
其次,Novogratz 將目光投向了香港,香港現已正式開始首次允許零售客戶在受監管的交易所進行加密貨幣交易,這表明亞洲采用率越來越高。[2023/6/2 11:54:33]
GPT-2也于2019年如期而至,不過,GPT-2并沒有對原有的網絡進行過多的結構創新與設計,只使用了更多的網絡參數與更大的數據集:最大模型共計48層,參數量達15億,學習目標則使用無監督預訓練模型做有監督任務。在性能方面,除了理解能力外,GPT-2在生成方面第一次表現出了強大的天賦:閱讀摘要、聊天、續寫、編故事,甚至生成假新聞、釣魚郵件或在網上進行角色扮演通通不在話下。在“變得更大”之后,GPT-2的確展現出了普適而強大的能力,并在多個特定的語言建模任務上實現了彼時的最佳性能。
BlockTower10小時前將125.01萬枚RSR轉移到Binance:金色財經報道,據Spot on Chain數據顯示,BlockTower Capital在10小時前以0.003美元(38.4961萬美元)的價格將125.01萬枚的RSR轉移到Binance。占交易量的6.11%。BlockTower Capital目前仍然在4個錢包中持有9.6348億枚美元RSR,價值約302萬美元,占流通量1.85%。可能間接導致了價格下跌2%,RSR價格在反彈前幾乎觸及歷史最低點。
值得注意的是,BlockTower 是2019 年Reserve的早期投資者之一。他們對RSR的成本仍然不確定。自3月31日以來,VC以0.004美元(價值約142萬美元)的平均價格向Binance轉移了總計3.7502億枚RSR,每次流出后價格都有明顯下降。[2023/5/31 11:49:30]
之后,GPT-3出現了,作為一個無監督模型,幾乎可以完成自然語言處理的絕大部分任務,例如面向問題的搜索、閱讀理解、語義推斷、機器翻譯、文章生成和自動問答等等。而且,該模型在諸多任務上表現卓越,例如在法語-英語和德語-英語機器翻譯任務上達到當前最佳水平,自動產生的文章幾乎讓人無法辨別出自人還是機器,更令人驚訝的是在兩位數的加減運算任務上達到幾乎100%的正確率,甚至還可以依據任務描述自動生成代碼。一個無監督模型功能多效果好,似乎讓人們看到了通用人工智能的希望,可能這就是GPT-3影響如此之大的主要原因
Odsy Network以2.5億美元估值完成750萬美元融資:5月11日消息,Layer 1 區塊鏈 Odsy Network 以 2.5 億美元估值完成 750 萬美元融資,本輪融資由 Blockchange Ventures 領投,Rubik Ventures、Node Capital 和 FalconX 等公司參投。
Odsy 的去中心化錢包 (dWallets) 旨在通過 Odsy 網絡上的“可轉讓簽名機制”提供對不同 Web3 協議和平臺的訪問,并能夠在幾乎任何其他區塊鏈上簽署交易。[2023/5/11 14:58:08]
GPT-3模型到底是什么?
實際上,GPT-3就是一個簡單的統計語言模型。從機器學習的角度,語言模型是對詞語序列的概率分布的建模,即利用已經說過的片段作為條件預測下一個時刻不同詞語出現的概率分布。語言模型一方面可以衡量一個句子符合語言文法的程度,同時也可以用來預測生成新的句子。例如,對于一個片段“中午12點了,我們一起去餐廳”,語言模型可以預測“餐廳”后面可能出現的詞語。一般的語言模型會預測下一個詞語是“吃飯”,強大的語言模型能夠捕捉時間信息并且預測產生符合語境的詞語“吃午飯”。
Aave社區關于“在以太坊主網上部署Aave V3”的提案投票獲得通過:1月26日消息,Aave社區關于“在以太坊主網上部署Aave V3”的提案投票獲得通過。提案顯示,Aave V3將會重新部署在以太坊主網上而并非升級V2版本,以提高V3池之間的兼容性并降低一般復雜性。Aave V3初始版本將上線WBTC、WETH、wstETH、USDC、DAI、LINK和AAVE七種資產的借貸池。[2023/1/26 11:31:14]
通常,一個語言模型是否強大主要取決于兩點:首先看該模型是否能夠利用所有的歷史上下文信息,上述例子中如果無法捕捉“中午12點”這個遠距離的語義信息,語言模型幾乎無法預測下一個詞語“吃午飯”。其次,還要看是否有足夠豐富的歷史上下文可供模型學習,也就是說訓練語料是否足夠豐富。由于語言模型屬于自監督學習,優化目標是最大化所見文本的語言模型概率,因此任何文本無需標注即可作為訓練數據。
由于GPT-3更強的性能和明顯更多的參數,它包含了更多的主題文本,顯然優于前代的GPT-2。作為目前最大的密集型神經網絡,GPT-3能夠將網頁描述轉換為相應代碼、模仿人類敘事、創作定制詩歌、生成游戲劇本,甚至模仿已故的各位哲學家——預測生命的真諦。且GPT-3不需要微調,在處理語法難題方面,它只需要一些輸出類型的樣本。可以說GPT-3似乎已經滿足了我們對于語言專家的一切想象。
幣安因漏洞錯誤地向用戶支付480萬枚HNT代幣,價值約1900萬美元:金色財經報道,知情人士稱,幣安的一個會計漏洞導致一些用戶在Helium Network的HNT代幣獲利,并使幣安承擔了數百萬美元的虧損。據悉,幣安減少了大約480萬枚HNT代幣,這些代幣被錯誤地發放給了用戶,其中許多人迅速出售了這些代幣以獲利。按照周五的價格,這些資產價值約1900萬美元。
Helium有兩種代幣,分別為MOBILE和HNT。幣安錯誤地將它們都算作HNT。向幣安地址發送MOBILE的存款人得到了同等數量且更有價值的HNT。該漏洞目前已被修復。(CoinDesk)[2022/9/17 7:02:24]
注:上文主要參考以下文章:1.GPT4發布在即堪比人腦,多位圈內大佬坐不住了!-徐杰承、云昭-公眾號51CTO技術棧-2022-11-2418:082.一文解答你對GPT-3的好奇!GPT-3是什么?為何說它如此優秀?-張家俊中國科學院自動化研究所2020-11-1117:25發表于北京3.TheBatch:329|InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-0712:30
GPT-3存在什么問題?
但是GTP-3并不完美,當前有人們最擔憂人工智能的主要問題之一,就是聊天機器人和文本生成工具等很可能會不分青紅皂白和質量好壞,地對網絡上的所有文本進行學習,進而生產出錯誤的、惡意冒犯的、甚至是攻擊性的語言輸出,這將會充分影響到它們的下一步應用。
OpenAI也曾經提出,會在不久的將來發布更為強大的GPT-4:

將?GPT-3與GPT-4、?人腦進行比較
據說,GPT-4會在明年發布,它能夠通過圖靈測試,并且能夠先進到和人類沒有區別,除此之外,企業引進GPT-4的成本也將大規模下降。
ChatGP與InstructGPT
ChatGPT與InstructGPT
談到Chatgpt,就要聊聊它的“前身”InstructGPT。
2022年初,OpenAI發布了InstructGPT;在這項研究中,相比GPT-3而言,OpenAI采用對齊研究,訓練出更真實、更無害,而且更好地遵循用戶意圖的語言模型InstructGPT,InstructGPT是一個經過微調的新版本GPT-3,可以將有害的、不真實的和有偏差的輸出最小化。
InstructGPT的工作原理是什么?
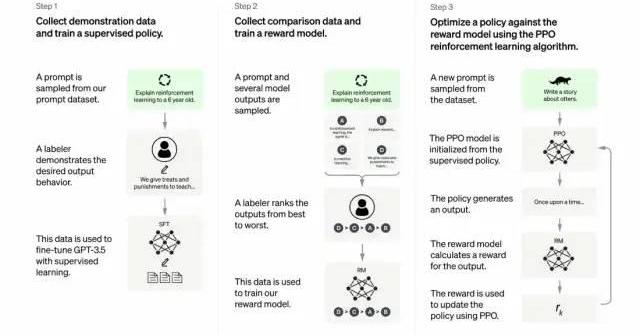
開發人員通過結合監督學習+從人類反饋中獲得的強化學習。來提高GPT-3的輸出質量。在這種學習中,人類對模型的潛在輸出進行排序;強化學習算法則對產生類似于高級輸出材料的模型進行獎勵。
訓練數據集以創建提示開始,其中一些提示是基于GPT-3用戶的輸入,比如“給我講一個關于青蛙的故事”或“用幾句話給一個6歲的孩子解釋一下登月”。
開發人員將提示分為三個部分,并以不同的方式為每個部分創建響應:
人類作家會對第一組提示做出響應。開發人員微調了一個經過訓練的GPT-3,將它變成InstructGPT以生成每個提示的現有響應。
下一步是訓練一個模型,使其對更好的響應做出更高的獎勵。對于第二組提示,經過優化的模型會生成多個響應。人工評分者會對每個回復進行排名。在給出一個提示和兩個響應后,一個獎勵模型(另一個預先訓練的GPT-3)學會了為評分高的響應計算更高的獎勵,為評分低的回答計算更低的獎勵。
開發人員使用第三組提示和強化學習方法近端策略優化(ProximalPolicyOptimization,PPO)進一步微調了語言模型。給出提示后,語言模型會生成響應,而獎勵模型會給予相應獎勵。PPO使用獎勵來更新語言模型。
本段參考:TheBatch:329|InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-0712:30
重要在何處?核心在于——人工智能需要是能夠負責任的人工智能
OpenAI的語言模型可以助力教育領域、虛擬治療師、寫作輔助工具、角色扮演游戲等,在這些領域,社會偏見、錯誤信息和害信息存在都是比較麻煩的,能夠避免這些缺陷的系統才能更具備有用性。
Chatgpt與InstructGPT的訓練過程有哪些不同?
總體來說,Chatgpt和上文的InstructGPT一樣,是使用RLHF訓練的。不同之處在于數據是如何設置用于訓練的。
ChatGPT存在哪些局限性?
如下:a)在訓練的強化學習(RL)階段,沒有真相和問題標準答案的具體來源,來答復你的問題。b)訓練模型更加謹慎,可能會拒絕回答。c)監督訓練可能會誤導/偏向模型傾向于知道理想的答案,而不是模型生成一組隨機的響應并且只有人類評論者選擇好的/排名靠前的響應
注意:ChatGPT對措辭敏感。,有時模型最終對一個短語沒有反應,但對問題/短語稍作調整,它最終會正確回答。訓練者更傾向于喜歡更長的答案,因為這些答案可能看起來更全面,導致傾向于更為冗長的回答,以及模型中會過度使用某些短語,如果初始提示或問題含糊不清,則模型不會適當地要求澄清。
Tags:GPTCHAUCTINSTGPT幣fazhanchainAUCTIONCrypto Against Cancer
注:本文來自@victalk_eth,整理如下:在翻譯Web3MOOC第四課的過程中,看到了關于常見的錯誤Web3創業思路的分類,感覺非常的有道理,所以發到推上和大家分享.
1900/1/1 0:00:00關鍵要點 ?FTX和Alameda的關系,從最初就有著密切的聯系。FTX發行FTX?Token(FTT),這是他們交易平臺的代幣,從第一天起就涉及Alameda.
1900/1/1 0:00:00?回溯數字社交的歷史 迄今為止,互聯網的每一次迭代都迎來了一項全新的技術,幫助我們更好地交流。最初,這興起于1988年的互聯網中繼聊天(IRC),至1990年代后期,我們看到了第一批主要的即時消.
1900/1/1 0:00:00本周,Pitchbook發布了最新的新興技術指標(ETI)報告,該報告跟蹤了全球最成功的風險投資公司的早期投資活動,以“衡量哪些科技領域正在吸引風險投資公司的注意力”.
1900/1/1 0:00:00王永利,中國國際期貨有限公司總經理、中國銀行原副行長繼FTX之后,BlockFi近期申請破產保護,已然開啟加密貨幣領域的“雷曼時刻”.
1900/1/1 0:00:00之前提到了假的protocol?@HookedProtocol,具體可以看我之前發的twitter,今天淺研了一下真的protocol?@pushprotocol,看看正經的協議到底是什么樣.
1900/1/1 0:00:00


