






 BTC/HKD+1.31%
BTC/HKD+1.31% ETH/HKD+1.22%
ETH/HKD+1.22% LTC/HKD+0.24%
LTC/HKD+0.24% DOT/HKD-0.39%
DOT/HKD-0.39% ADA/HKD+0.71%
ADA/HKD+0.71% SOL/HKD+2.28%
SOL/HKD+2.28% XRP/HKD+0.19%
XRP/HKD+0.19% DOGE/US+1.66%
DOGE/US+1.66%核心提示:
ChatGPT等基于自然語言處理技術的聊天AI,就短期來看亟需要解決的法律合規問題主要有三個:
其一,聊天AI提供的答復的知識產權問題,其中最主要的合規難題是聊天AI產出的答復是否產生相應的知識產權?是否需要知識產權授權?;
其二,聊天AI對巨量的自然語言處理文本進行數據挖掘和訓練的過程是否需要獲得相應的知識產權授權?
其三,ChatGPT等聊天AI的回答是機制之一是通過對大量已經存在的自然語言文本進行數學上的統計,得到一個基于統計的語言模型,這一機制導致聊天AI很可能會“一本正經的胡說八道”,進而導致虛假信息傳播的法律風險,在這一技術背景下,如何盡可能降低聊天AI的虛假信息傳播風險?
總體而言,目前我國對于人工智能立法依然處在預研究階段,還沒有正式的立法計劃或者相關的動議草案,相關部門對于人工智能領域的監管尤為謹慎,隨著人工智能的逐步發展,相應的法律合規難題只會越來越多。
ChatGPT并非是“跨時代的人工
智能技術”
ChatGPT本質上是自然語言處理技術發展的產物,本質上依然僅是一個語言模型。
2023開年之初全球科技巨頭微軟的巨額投資讓ChatGPT成為科技領域的“頂流”并成功出圈。隨著資本市場ChatGPT概念板塊的大漲,國內眾多科技企業也著手布局這一領域,在資本市場熱捧“ChatGPT概念的同時,作為法律工作者,我們不禁要評估ChatGPT自身可能會帶來哪些法律安全風險,其法律合規路徑何在?
直播|Sharon Luo > DeFi熱度是投機泡沫還是區塊鏈革命:金色財經 · 直播主辦的《 幣圈 “后浪” 仙女直播周》第12期15:00準時開始,本期“后浪”仙女元界的市場負責人/Tokenism的聯合創始人Sharon Luo將在直播間聊聊“DeFi熱度是投機泡沫還是區塊鏈革命”,請掃碼移步收聽![2020/8/14]
在討論ChatGPT的法律風險及合規路徑之前,我們首先應當審視ChatGPT的技術原理——ChatGPT是否如新聞所言一樣,可以給提問者任何其想要的問題?
在颯姐團隊看來,ChatGPT似乎遠沒有部分新聞所宣傳的那樣“神”——一句話總結,其僅僅是Transformer和GPT等自然語言處理技術的集成,本質上依然是一個基于神經網絡的語言模型,而非一項“跨時代的AI進步”。
前面已經提到ChatGPT是自然語言處理技術發展的產物,就該技術的發展史來看,其大致經歷了基于語法的語言模型——基于統計的語言模型——基于神經網絡的語言模型三大階段,ChatGPT所在的階段正是基于神經網絡的語言模型階段,想要更為直白地理解ChatGPT的工作原理及該原理可能引發的法律風險,必須首先闡明的就是基于神經網絡的語言模型的前身——基于統計的語言模型的工作原理。
在基于統計的語言模型階段,AI工程師通過對巨量的自然語言文本進行統計,確定詞語之間先后連結的概率,當人們提出一個問題時,AI開始分析該問題的構成詞語共同組成的語言環境之下,哪些詞語搭配是高概率的,之后再將這些高概率的詞語拼接在一起,返回一個基于統計學的答案。可以說這一原理自出現以來就貫穿了自然語言處理技術的發展,甚至從某種意義上說,之后出現的基于神經網絡的語言模型亦是對基于統計的語言模型的修正。
動態 | “區塊鏈”近7日搜索熱度整體同比上漲45%:今日百度搜索熱度中,“區塊鏈”的搜索熱度近7日整體日均值為10621,整體同比上漲68%,環比下降12%。“比特幣”的搜索熱度近30日整體日均值為20236,整體同比下跌24%,環比下跌14%。[2019/12/17]
舉一個容易理解的例子,颯姐團隊在ChatGPT聊天框中輸入問題“大連有哪些旅游勝地?”如下圖所示:
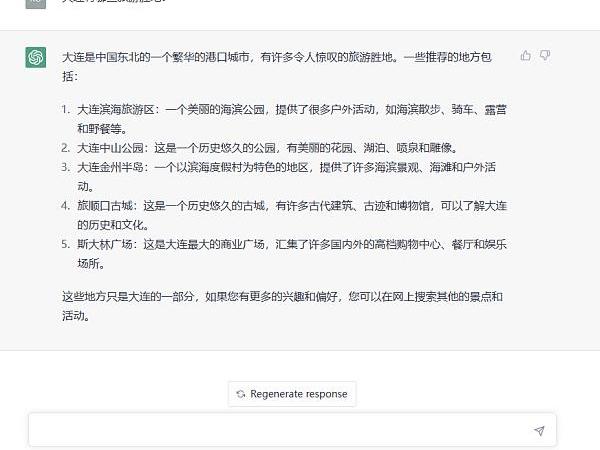
AI第一步會分析問題中的基本語素“大連、哪些、旅游、勝地”,再在已有的語料庫中找到這些語素所在的自然語言文本集合,在這個集合中找尋出現概率最多的搭配,再將這些搭配組合以形成最終的答案。如AI會發現在“大連、旅游、勝地”這三個詞高概率出現的語料庫中,有“中山公園”一詞,于是就會返回“中山公園”,又如“公園”這個詞與花園、湖泊、噴泉、雕像等詞語搭配的概率最大,因此就會進一步返回“這是一個歷史悠久的公園,有美麗的花園、湖泊、噴泉和雕像。”
換言之,整個過程都是基于AI背后已有的自然語言文本信息進行的概率統計,因此返回的答案也都是“統計的結果”,這就導致了ChatGPT在許多問題上會“一本正經的胡說八道”。如剛才的這個問題“大連有哪些旅游勝地”的回答,大連雖然有中山公園,但是中山公園中并沒有湖泊、噴泉和雕像。大連在歷史上的確有“斯大林廣場”,但是斯大林廣場自始至終都不是一個商業廣場,也沒有任何購物中心、餐廳和娛樂場所。顯然,ChatGPT返回的信息是虛假的。
動態 | 谷歌趨勢:“比特幣”搜索熱度區域排名巴西進入前三:據Google Trends數據,過去7天的搜索熱度中,尼日利亞成為搜索“bitcoin”熱度最高的地區。在按區域顯示的“bitcoin”搜索熱度排行中,前五名依次是:尼日利亞、南非、巴西、奧地利以及瑞士。全球“blockchain”熱度最高的5個國家/地區為:韓國、俄羅斯、香港、烏克蘭、加納。[2019/8/11]
ChatGPT作為語言模型目前其
最適合的應用場景
雖然上個部分我們直白的講明了基于統計的語言模型的弊端,但ChatGPT畢竟已經是對基于統計的語言模型大幅度改良的基于神經網絡的語言模型,其技術基礎Transformer和GPT都是最新一代的語言模型,ChatGPT本質上就是將海量的數據結合表達能力很強的Transformer模型結合,從而對自然語言進行了一個非常深度的建模,返回的語句雖然有時候是“胡說八道”,但乍一看還是很像“人類回復的”,因此這一技術在需要海量的人機交互的場景下具有廣泛的應用場景。
就目前來看,這樣的場景有三個:
其一,搜索引擎;
其二,銀行、律所、各類中介機構、商場、醫院、政府政務服務平臺中的人機交互機制,如上述場所中的客訴系統、導診導航、政務咨詢系統;
第三,智能汽車、智能家居等的交互機制。
動態 | 近半年“比特幣”搜索熱度整體同比下跌45%:今日百度搜索熱度中,“區塊鏈”的搜索熱度近半年整體日均值為7496,整體同比下跌8%,環比下跌64%。“比特幣”的搜索熱度近半年整體日均值為22923,整體同比下跌45%,環比下跌37%。“以太坊”的搜索熱度近半年整體日均值為4688,整體同比上升68%,環比下跌15%。[2019/1/27]
結合ChatGPT等AI聊天技術的搜索引擎很可能會呈現出傳統搜索引擎為主+基于神經網絡的語言模型為輔的途徑。目前傳統的搜索巨頭如谷歌和百度均在基于神經網絡的語言模型技術上有著深厚的積累,譬如谷歌就有與ChatGPT相媲美的Sparrow和Lamda,有著這些語言模型的加持,搜索引擎將會更加“人性化”。
ChatGPT等AI聊天技術運用在客訴系統和醫院、商場的導診導航以及政府機關的政務咨詢系統中將大幅度降低相關單位的人力資源成本,節約溝通時間,但問題在于基于統計的回答有可能產生完全錯誤的內容回復,由此帶來的風控風險恐怕還需要進一步評估。
相比于上述兩個應用場景,ChatGPT應用在智能汽車、智能家居等領域成為上述設備的人機交互機制的法律風險則要小很多,因為這類領域應用環境較為私密,AI反饋的錯誤內容不至于引起大的法律風險,同時這類場景對內容準確性要求不高,商業模式也更為成熟。三
ChatGPT的法律風險及合規路徑
動態 | 區塊鏈百度搜索熱度移動同比上漲238%:百度搜索指數“區塊鏈”的搜索熱度近7日整體日均值為4619,整體同比上漲147%,移動同比上漲238% ;“比特幣”的搜索熱度近7日整體日均值為12762,整體同比下降36%,移動同比下降23%;“以太坊”的搜索熱度近7日整體日均值為3174,整體同比上升138%,移動同比上漲291%。[2018/10/7]
初探
第一,人工智能在我國的整體監管圖景
和許多新興技術一樣,ChatGPT所代表的自然語言處理技術也面臨著“科林格里奇窘境”這一窘境包含了信息困境與控制困境,所謂信息困境,即一項新興技術所帶來的社會后果不能在該技術的早期被預料到;所謂控制困境,即當一項新興技術所帶來的不利的社會后果被發現時,技術卻往往已經成為整個社會和經濟結構的一部分,致使不利的社會后果無法被有效控制。
目前人工智能領域,尤其是自然語言處理技術領域正在快速發展階段,該技術很可能會陷入所謂的“科林格里奇窘境”,與此相對應的法律監管似乎并未“跟得上步伐”。我國目前尚無國家層面上的人工智能產業立法,但地方已經有相關的立法嘗試。就在去年9月,深圳市公布了全國收不人工智能產業專項立法《深圳經濟特區人工智能產業促進條例》,緊接著上海也通過了《上海市促進人工智能產業發展條例》,相信不久之后各地均會出臺類似的人工智能產業立法。
在人工智能的倫理規制方面,國家新一代人工智能治理專業委員會亦在2021年發布了《新一代人工智能倫理規范》,提出將倫理道德融入人工智能研發和應用的全生命周期,或許在不久的將來,類似阿西莫夫小說中的“機器人三定律”將成為人工智能領域監管的鐵律。
第二,ChatGPT帶來的虛假信息法律風險問題
將目光由宏觀轉向微觀,拋開人工智能產業的整體監管圖景和人工智能倫理規制問題,ChatGPT等AI聊天基礎存在的現實合規問題也急需重視。
這其中較為棘手的是ChatGPT回復的虛假信息問題,正如本文在第二部分提及的,ChatGPT的工作原理導致其回復可能完全是“一本正經的胡說八道”,這種看似真實實則離譜的虛假信息具有極大的誤導性。當然,像對“大連有哪些旅游勝地”這類問題的虛假回復可能不會造成嚴重后果,但倘若ChatGPT應用到搜索引擎、客訴系統等領域,其回復的虛假信息可能造成極為嚴重的法律風險。
實際上這樣的法律風險已經出現,2022年11月幾乎與ChatGPT同一時間上線的Meta服務科研領域的語言模型Galactica就因為真假答案混雜的問題,測試僅僅3天就被用戶投訴下線。在技術原理無法短時間突破的前提下,倘若將ChatGPT及類似的語言模型應用到搜索引擎、客訴系統等領域,就必須對其進行合規性改造。當檢測到用戶可能詢問專業性問題時,應當引導用戶咨詢相應的專業人員,而非在人工智能處尋找答案,同時應當顯著提醒用戶聊天AI返回的問題真實性可能需要進一步驗證,以最大程度降低相應的合規風險。
第三,ChatGPT帶來的知識產權合規問題
當將目光由宏觀轉向微觀時,除了AI回復信息的真實性問題,聊天AI尤其是像ChatGPT這樣的大型語言模型的知識產權問題亦應該引起合規人員的注意。
首先的合規難題是“文本數據挖掘”是否需要相應的知識產權授權問題。正如前文所指明的ChatGPT的工作原理,其依靠巨量的自然語言本文,ChatGPT需要對語料庫中的數據進行挖掘和訓練,ChatGPT需要將語料庫中的內容復制到自己的數據庫中,相應的行為通常在自然語言處理領域被稱之為“文本數據挖掘”。當相應的文本數據可能構成作品的前提下,文本數據挖掘行為是否侵犯復制權當前仍存在爭議。
在比較法領域,日本和歐盟在其著作權立法中均對合理使用的范圍進行了擴大,將AI中的“文本數據挖掘”增列為一項新的合理使用的情形。雖然2020年我國著作權法修法過程中有學者主張將我國的合理使用制度由“封閉式”轉向“開放式”,但這一主張最后并未被采納,目前我國著作權法依舊保持了合理使用制度的封閉式規定,僅著作權法第二十四條規定的十三中情形可以被認定為合理使用,換言之,目前我國著作權法并未將AI中的“文本數據挖掘”納入到合理適用的范圍內,文本數據挖掘在我國依然需要相應的知識產權授權。
其次的合規難題是ChatGPT產生的答復是否具有獨創性?對于AI生成的作品是否具有獨創性的問題,颯姐團隊認為其判定標準不應當與現有的判定標準有所區別,換言之,無論某一答復是AI完成的還是人類完成的,其都應當根據現有的獨創性標準進行判定。其實這個問題背后是另一個更具有爭議性的問題,如果AI生成的答復具有獨創性,那么著作權人可以是AI嗎?顯然,在包括我國在內的大部分國家的知識產權法律下,作品的作者僅有可能是自然人,AI無法成為作品的作者。
最后,ChatGPT倘若在自己的回復中拼接了第三方作品,其知識產權問題應當如何處理?颯姐團隊認為,如果ChatGPT的答復中拼接了語料庫中擁有著作權的作品,那么按照中國現行的著作權法,除非構成合理使用,否則非必須獲得著作權人的授權后才可以復制。
據悉,南方某省市場監督管理局、宣傳部、網信辦、工信廳、文旅廳、商務廳、廳、金融局、稅務局、通信局聯合發布:《關于加強數字藏品風險監管工作的通知》對省內數字藏品風險加強監管.
1900/1/1 0:00:0021:00-7:00關鍵詞:SWOOSH、dYdX、Circle、ENS1.愛爾蘭央行行長呼吁禁止加密貨幣廣告;2.Proof首席執行官兼聯合創始人個人錢包遭黑客攻擊;3.
1900/1/1 0:00:00近期,跨平臺的即時通訊軟件Telegram盜號事件頻發,不法分子通過非法手段盜取用戶Telegram賬號,并以冒充好友的方式進行詐騙.
1900/1/1 0:00:00文:蘇子華 “Web3和區塊鏈不是等號。”DraperDragon合伙人王岳華對36氪表示。DraperDragon成立于2006年,是一家活躍于中美的風險投資基金,投資領域涵蓋智能制造、生物醫.
1900/1/1 0:00:00通常來說,NFT地板價可以讓市場參與者洞察到NFT項目在藏品級別的公允市場價值。NFT買家在分析并做出購買決策的過程中可以參考NFT地板價來聚焦,消除藏品內在因素的干擾,比如稀有性以及其他屬性.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:477.31億美元 DeFi總市值及前十代幣數據來源:coingecko2、過去24小時去中心化交易所的交易量20.
1900/1/1 0:00:00


