






 BTC/HKD+2.44%
BTC/HKD+2.44% ETH/HKD+1.77%
ETH/HKD+1.77% LTC/HKD+2.77%
LTC/HKD+2.77% DOT/HKD+1.68%
DOT/HKD+1.68% ADA/HKD+4.12%
ADA/HKD+4.12% SOL/HKD+3.67%
SOL/HKD+3.67% XRP/HKD+2.19%
XRP/HKD+2.19% DOGE/US+3.83%
DOGE/US+3.83%眾所周知,OpenAI并不“open”,特別是在GPT-4發布后,整個OpenAI團隊對GPT-4的幾乎所有信息都守口如瓶。
而就在今天上午,媒體semianalysis的DylanPatel和GeraldWong發表了一篇題為《GPT-4Architecture,Infrastructure,TrainingDataset,Costs,Vision,MoE》的文章,曝光了GPT-4從模型架構、模型訓練到成本的所有細節,GPT-4又被“開源”了?
文章中詳細介紹了GPT-4的架構、訓練和推理的基礎設施、參數量、訓練數據集、token數、成本、混合專家模型等非常具體的參數和信息。
同時還“深扒了”在不同的路線選擇上,OpenAI面臨的各類權衡,并直言,對GPT-4而言,最有趣的是理解OpenAI為什么會做出某些架構決策。

https://www.semianalysis.com/p/gpt-4-architecture-infrastructure值得注意的是,DylanPatel同樣也是谷歌內部文件泄漏事件的作者。

而DeepMindCEOHassabis近日在接受媒體采訪時,確認了這份谷歌被泄漏的文件的真實性。
鑒于爆料者是DylanPatel,此次GPT-4“大揭秘”的真實性又提高了幾分。
文章開頭就指出,OpenAI之所以不open,不是為了保護人類不被AI毀滅,而是因為他們構建的大模型是可復制的,未來中國和美國的互聯網大廠及AI頭部初創企業,都會有能力構建出可以和GPT-4媲美甚至超越GPT-4的大模型。
而OpenAI最持久的護城河,就在于他們擁有真實用戶的使用反饋,業內最頂尖的工程人才,以及先發優勢帶來的領先地位。
華爾街見聞整理了關于GPT-4爆料的主要內容:
1.8萬億巨量參數和模型框架
文章指出,GPT-4在120層中總共包含了1.8萬億參數,而GPT-3只有約1750億個參數。也就是說,GPT-4的規模是GPT-3的10倍以上。
OpenAI通過使用混合專家模型來控制成本。GPT-4擁有16個專家模型,每個MLP專家大約有1110億個參數。其中,有兩個專家模型被用于前向傳播。
OpenAI用于GPT-4的算法,其實非常簡單。模型中還有約550億個參數,被用做注意力機制的共享。
每次的前向傳播推理中,GPT-4只需要使用大約2800億參數和560TFLOPs。相比之下,純密集模型每次前向傳播需要大約1.8萬億個參數和約3700TFLOP的計算量。
數據集的構成
OpenAI用13萬億的token訓出了GPT-4。因為沒有高質量的token,這個數據集還包含了許多個epoch。
Epoch數量:針對基于文本的數據進行2個epoch的訓練,而針對基于代碼的數據進行了4個epoch的訓練。
在預訓練階段,GPT-4使用了8k的上下文長度,而32k的版本是基于預訓練后的8K版本微調而來的。
在幾天之內批大小在集群中逐漸增加。最終OpenAI使用的批大小達到了6000萬,當然,由于并非每個專家模型都能看到所有token,因此這僅為每個750萬token的專家模型的大小
機構:全球75%的企業正在實施或考慮禁止在工作場所使用ChatGPT等:金色財經報道,BlackBerry發布的一份研究報告顯示,全球75%的企業正在實施或考慮在工作場所禁止ChatGPT和其他生成式AI應用程序。在部署或考慮實施禁令的企業中,有61%表示這些禁令是長期或永久性的,主要是出于對數據安全、隱私和企業聲譽的風險考慮,另有83%表示擔心不安全的應用會對其企業IT環境帶來網絡安全威脅。[2023/8/10 16:18:00]
真實的批處理大小:將這個數字除以序列長度即可得到。
OpenAI的并行策略
并行策略對于A100GPU是相當重要的。為了在所有A100GPU上進行并行計算,OpenAI采用了8路張量并行,因為這是NVLink的極限。除此之外,據說OpenAI采用15路并行管線。
理論上,考慮到數據通信和計算時間,15個管線就有些多了。但是一旦加上了KV緩存和成本,如果OpenAI使用的GPU大部分是40GB的A100,那這樣的構架在理論上就是有意義的。
但作者表示,他并不是太明白OpenAI在如此高的管線并行度下,如何避免在每批中產生如下圖這樣的“泡泡”,很有可能OpenAI就是生生地抗下了這些成本。
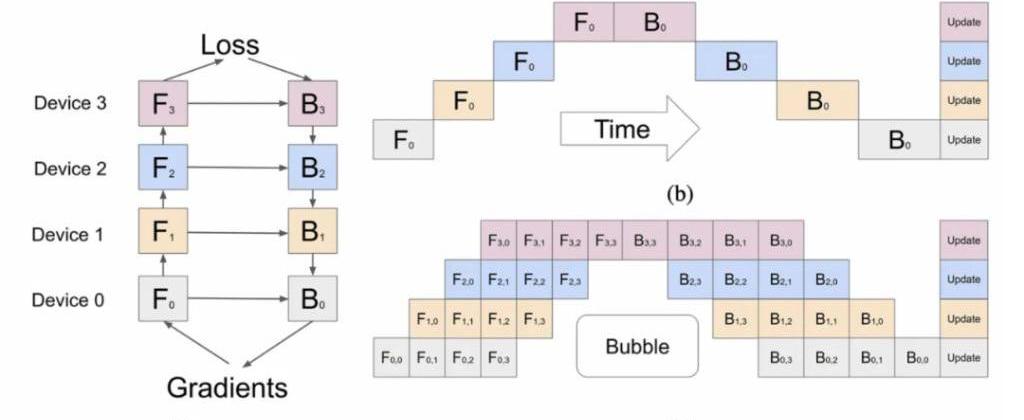
訓練成本:一次的訓練的成本為6300萬美元
OpenAI訓練GPT-4的FLOPS約為2.15e25,在大約25000個A100上訓練了90到100天,利用率在32%到36%之間。故障數量過多也是極低利用率的原因,這會導致需要重新從之前的檢查點開始訓練。
另一個原因是這么多GPU之間的all-reduce非常昂貴。
如果OpenAI云計算的成本是差不多1美元/每A100小時的話,那么在這樣的條件下,僅這次訓練的成本大約是6300萬美元。
這還不包括所有的實驗、失敗的訓練和其他成本,比如數據收集、RLHF、人力成本等。
如果考慮到剛剛說的這些因素,真實成本要高得多的多。
但是放到今天,在2美元/每H100小時的條件下,預訓練可以在大約8192個H100上進行,只需要55天,費用為2150萬美元。
使用專家混合模型時的權衡
MoE是一種在推理過程中減少參數量的很好方法,但同時他會增加參數量。
如果OpenAI真的想追求最佳性能,他們需要訓練兩倍的token才能達到。
采用相對比較少的專家模型的原因很多,OpenAI選擇16個專家的原因之一在于,在執行許多任務上,更多的專家模型很難泛化,也更難實現收斂。
GPT-4推理成本
與擁有1750億參數的Davinchi模型相比,GPT-4的成本是其3倍,盡管其前饋參數只增加了1.6倍。這主要是因為GPT-4需要更大的集群,并且實現的利用率更低。
作者認為,在用128個A100GPU進行推理的情況下,GPT-4的8k序列長度每1000個標記的成本為0.0049美元,而在128個H100上推理GPT-4的8k序列長度每1000個標記的成本為0.0021美元。
需要注意的是,這是假設有相當高的利用率,并保持較高批大小的情況下。但很明顯,OpenAI有時的利用率非常低。
多查詢注意力
OpenAI:所有付費API客戶都可以訪問GPT-4:金色財經報道,OpenAI的官網顯示,從7月6日開始,所有付費API客戶都可以訪問GPT-4。本月早些時候,他們發布了對基于聊天的模型的第一次更新。他們設想未來基于聊天的模型可以支持任何案例。而當前,他們宣布了一項針對舊型號的Completions API的棄用計劃,并建議用戶采用Chat Completions API。OpenAI表示,現有的API開發者將可以使用擁有8K上下文能力的GPT-4 API。此外他們計劃在本月底向新開發人員開放訪問權限,然后根據計算可用性開始提高速率限制。[2023/7/7 22:24:30]
OpenAI和其他大廠一樣,也在使用MQA。
簡單來說只需要一個注意力頭,并且可以顯著減少KV緩存的內存占用。即便如此,32k長度的GPT-4肯定無法在40GB的A100上運行,而8k的最大批大小也有上限。
連續批處理
OpenAI實現了可變批大小和連續批處理。
這樣做是為了允許一定程度的最大延遲,并優化推理成本。
推測解碼
OpenAI在GPT-4的推理過程中使用了“推測解碼”。
“推測解碼”的基本原理是使用一個更小、更快的草案模型提前解碼多個token,然后將它們作為一個批輸入到預測模型中。如果OpenAI使用“推測解碼”,他們可能只在大約4個token的序列中使用。
視覺多模態
它是一個獨立于文本編碼器的視覺編碼器,二者之間存在交叉注意力,該架構類似于Flamingo。這在GPT-4的1.8萬億個參數之上增加了更多參數。
GPT-4多模態能力是在文本預訓練之后,又用大約2萬億token進?了微調。據稱,在視覺模型上,OpenAI原本希望從頭開始訓練,但因其不夠成熟,無奈從文本訓練模型進行微調。
而下一代模型GPT-5,將從頭開始進行視覺訓練,并且也能自己生成圖像,甚至生成音頻。
以下為有新Newin通過GPT翻譯的全文:
OpenAI保持GPT-4架構封閉,不是因為對人類的某種存在風險,而是因為他們所構建的內容是可復制的。實際上,我們預計Google、Meta、Anthropic、Inflection、Character、Tencent、ByteDance、Baidu等公司在短期內將擁有與GPT-4一樣甚至更強大的模型能力。
請不要誤解,OpenAI具有令人驚嘆的工程能力,他們所構建的東西令人難以置信,但他們所找到的解決方案并非魔法。這是一個優雅的解決方案,其中包含許多復雜的權衡。規模擴大只是戰斗的一部分。OpenAI最持久的競爭優勢在于他們擁有最多的實際應用、領先的工程人才,并且可以通過未來的模型繼續超越其他公司。
我們從多個來源收集了關于GPT-4的大量信息,今天我們想分享一下。這包括模型架構、訓練基礎設施、推理基礎設施、參數數量、訓練數據集組成、令牌數量、層數量、并行策略、多模態視覺適應、不同工程權衡背后的思考過程、實施的獨特技術以及他們如何減輕與龐大模型推理相關的一些最大瓶頸。
GPT-4最有趣的方面是理解他們為什么做出某些架構決策。
此外,我們將概述在A100上訓練和推理GPT-4的成本,以及在下一代模型架構中如何與H100進行擴展。
首先,讓我們來看看問題陳述。從GPT-3到4,OpenAI希望擴大100倍,但問題是成本。密集的Transformer模型將無法進一步擴展。密集的Transformer是OpenAIGPT-3、GooglePaLM、MetaLLAMA、TIIFalcon、MosaicMLMPT等模型使用的模型架構。我們可以輕松地列舉出使用這種相同架構訓練LLM的50多家公司。這是一個不錯的架構,但對于擴展來說有缺陷。
Hedera網絡的ChatGPT插件上線,用戶可以通過Network Explorer查看帳戶余額:金色財經報道,Network Explorer開發人員EdMarquez表示,用戶可以通過Network Explorer查看帳戶余額,或通過插件將使用的鏡像節點RESTAPI以編程方式檢索帳戶余額。通過使用插件,ChatGPT與Hedera網絡的集成允許從Hedera賬戶檢索HBAR和代幣余額。[2023/6/25 21:59:21]
在GPT-4發布之前,我們曾討論過訓練成本與即將到來的AI磚墻之間的關系。在那里,我們揭示了OpenAI在GPT-4架構和各種現有模型的訓練成本方面的高層次做法。
在過去的六個月中,我們意識到訓練成本是無關緊要的。
當然,表面上看起來很瘋狂,要花費數千萬甚至數億美元的計算時間來訓練一個模型,但對于這些公司來說,這是微不足道的開支。這實際上是一項固定資本支出,在擴大規模方面始終能夠取得更好的結果。唯一的限制因素是將計算規模擴展到人類可以獲得反饋并修改架構的時間尺度上。
在未來的幾年里,像Google、Meta和OpenAI/Microsoft這樣的多家公司將在價值超過一千億美元的超級計算機上訓練模型。Meta每年在"Metaverse"上燒掉160億美元,Google每年在各種項目上浪費100億美元,Amazon在Alexa上損失超過500億美元,加密貨幣在毫無價值的事物上浪費了1000億美元以上。
這些公司和整個社會可以并且將會在創建可以訓練單個巨大模型的超級計算機上花費超過一千億美元。然后,這些巨大的模型可以以多種方式成為產品。這項工作將在多個國家和公司中復制。這是一場新的太空競賽。與以前的浪費不同,現在的人工智能具有實實在在的價值,短期內將從人類助手和自主代理中獲得。
擴展人工智能更重要的問題是推理。
目標是將訓練計算與推理計算分離。這就是為什么有意義的訓練超出Chinchilla最佳的范圍,無論將要部署的模型如何。這就是為什么要使用稀疏模型架構;在推理過程中,并不需要激活每個參數。
真正的挑戰是將這些模型擴展到用戶和代理的成本太高。推理的成本比訓練的成本高出多倍。這是OpenAI在模型架構和基礎設施方面的創新目標。
大型模型的推理是一個多變量問題,對于密集模型來說,模型大小是致命的。我們在這里詳細討論了與邊緣計算相關的問題,但數據中心的問題陳述非常相似。簡單來說,設備永遠無法擁有足夠的內存帶寬來實現大語言模型的特定吞吐量水平。即使帶寬足夠,邊緣計算設備上硬件計算資源的利用率也將非常低。
在數據中心、云端,利用率是至關重要的。Nvidia之所以因其卓越的軟件而受到贊賞,其中一半的原因是因為在GPU的整個生命周期中,Nvidia不斷更新低級別軟件,通過更智能地在芯片內部、芯片之間和內存之間移動數據,將FLOPS的利用率提高。
在大多數當前使用案例中,LLM推理的目標是作為實時助手運行,這意味著它必須達到足夠高的吞吐量,使用戶能夠真正使用它。人類平均閱讀速度約為每分鐘250個詞,但有些人甚至高達每分鐘1000個詞。這意味著您需要至少每秒輸出8.33個令牌,但更接近每秒輸出33.33個令牌以應對所有情況。
根據內存帶寬的要求,一個兆參數的密集模型在最新的NvidiaH100GPU服務器上數學上無法實現這種吞吐量。
每個生成的令牌都需要將每個參數從內存加載到芯片上。生成的令牌然后輸入到提示中,并生成下一個令牌。此外,為注意力機制流式傳輸KV緩存還需要額外的帶寬。
?OpenAI:將在未來幾個月推出ChatGPT企業版訂閱服務:金色財經報道,OpenAI表示,正在研究推出新企業版ChatGPT訂閱服務,主要針對那些希望更多掌控數據的專業人士以及尋求管理終端用戶的企業。“我們計劃在未來幾個月內推出企業版”,該公司還表示,已經引入關閉ChatGPT聊天記錄的功能。(鞭牛士)[2023/4/30 14:35:09]
4訓練成本
OpenAI在GPT-4的訓練中,使用了大約25,000個A100芯片,在90至100天的時間內進行了約32%至36%的MFU。這種極低的利用率部分是由于大量的故障導致需要從檢查點重新啟動的原因,上述提到的氣泡代價非常高。
另一個原因是在這么多GPU之間進行全局歸約的代價非常高。如果我們的猜測是正確的,那么該集群實際上是由許多較小的集群組成的,它們之間的網絡連接非常薄弱,即集群的不同部分之間的非阻塞連接為800G/1.6T,但這些部分只能以200G/400G的速度連接起來。
如果他們在云中的成本約為每小時1美元的A100芯片,僅這次訓練的成本就約為6300萬美元。這還沒有考慮到所有的實驗、失敗的訓練運行和其他成本,比如數據收集、強化學習和人員成本等。由于這些因素,實際成本要高得多。此外,這意味著您需要有人購買芯片/網絡/數據中心、承擔資本支出并將其租給您。
目前,使用約8,192個H100芯片,以每小時2美元的價格,在約55天內可以完成預訓練,成本約為2150萬美元。需要注意的是,我們相信到今年年底將有9家公司將擁有更多的H100芯片。并非所有這些公司都會將它們全部用于單次訓練運行,但那些這樣做的公司將會擁有更大規模的模型。Meta將在今年年底擁有超過10萬個H100芯片,但其中相當多的芯片將分布在他們的數據中心用于推理。他們最大的單個集群仍然將超過25,000個H100芯片。
到今年年底,很多公司將擁有足夠的計算資源來訓練與GPT-4規模相當的模型。
5MoE的權衡
在推理過程中,MoE是一種很好的方式,可以在推理時減少參數數量,同時增加參數數量,這對于編碼更多的信息每個訓練令牌是必需的,因為獲取足夠的高質量令牌非常困難。如果OpenAI真的試圖實現Chinchilla最佳化,他們將不得不在訓練中使用兩倍于目前的令牌數量。
盡管如此,OpenAI做出了多個權衡。例如,在推理過程中,MoE非常難處理,因為模型的每個部分在每個令牌生成時都不會被使用。這意味著在為用戶提供服務時,某些部分可能處于閑置狀態,而其他部分則正在使用。這對利用率產生了很大的負面影響。
研究人員已經表明,使用64到128個專家比使用16個專家的損失更小,但那只是純粹的研究結果。減少專家的數量有多個原因。OpenAI選擇16個專家的原因之一是因為更多的專家在許多任務上很難進行泛化。使用更多的專家也可能更難實現收斂。在如此大規模的訓練運行中,OpenAI選擇在專家數量上更保守一些。
此外,減少專家的數量還有助于他們的推理基礎設施。在采用專家混合推理架構時,存在各種困難的權衡。在探討OpenAI面臨的權衡和他們所做的選擇之前,我們先從LLM的推理基本權衡開始。
6推理的權衡
順便說一下,在開始之前,我們想指出,我們與所有LLM公司交談過的人都認為Nvidia的FasterTransformer推理庫相當糟糕,TensorRT則更糟。無法使用Nvidia的模板并進行修改的缺點意味著人們需要從零開始創建自己的解決方案。如果你是Nvidia的工作人員,閱讀這篇文章后,你需要盡快解決這個問題,否則默認的選擇將變為開放工具,這樣第三方硬件支持可以更容易地添加進來。一波巨大的模型即將到來。如果在推理方面沒有軟件優勢,并且仍然需要手工編寫內核,那么AMD的MI300和其他硬件將有更大的市場。
ChatGPT暫停Plus付費,理由是需求量太大:4月5日消息,據媒體報道,ChatGPT目前已停止Plus付費,OpenAI給出的理由是需求量太大。此前ChatGPT就因出現大規模封號引發熱議,以及馬斯克等領銜的暫停研發GPT4以上大模型的簽名信也引起業界極大關注。(鞭牛士 )[2023/4/5 13:45:44]
在大型語言模型的推理中,有3個主要的權衡,它們發生在批量大小和使用的芯片數量之間。
延遲-模型必須以合理的延遲做出響應。人們不想在等待輸出開始流入聊天應用程序之前等待幾秒鐘。預加載和解碼需要不同的時間來處理。吞吐量-模型必須以每秒輸出一定數量的令牌。大約每秒30個令牌是人類使用所需的。對于其他各種用途,較低和較高的吞吐量都可以接受。利用率-運行模型的硬件必須實現高利用率,否則成本將過高。雖然可以使用更高的延遲和較低的吞吐量將更多用戶請求進行分組,從而實現更高的利用率,但這會增加難度。LLM的推理完全是關于平衡兩個主要因素:內存帶寬和計算。在最過度簡化的術語中,每個參數都必須讀取,并且與之相關聯的是2個FLOP。因此,大多數芯片的比例在批量大小為1的推理中完全不平衡。如果只為一個用戶提供服務,批量大小為1,那么為了每個令牌生成,所需的內存帶寬主導推理時間。計算時間幾乎為零。為了有效地將大型語言模型擴展到多個用戶,批量大小必須超過4。多個用戶會分攤參數讀取的成本。例如,對于批量大小為256或512,每個字節的內存讀取有512個FLOP/s或1024個FLOP/s。
這個比例更接近于H100的內存帶寬與FLOPS之間的比例。這有助于實現更高的利用率,但代價是更高的延遲。
許多人將內存容量視為LLM推理的一個主要瓶頸,原因是大型模型需要多個芯片進行推理,而較大的內存容量會使其適應的芯片數量減少,但實際上,最好使用超過所需容量的芯片,以便將延遲降低,提高吞吐量,并且可以使用更大的批量大小來實現越來越高的利用率。
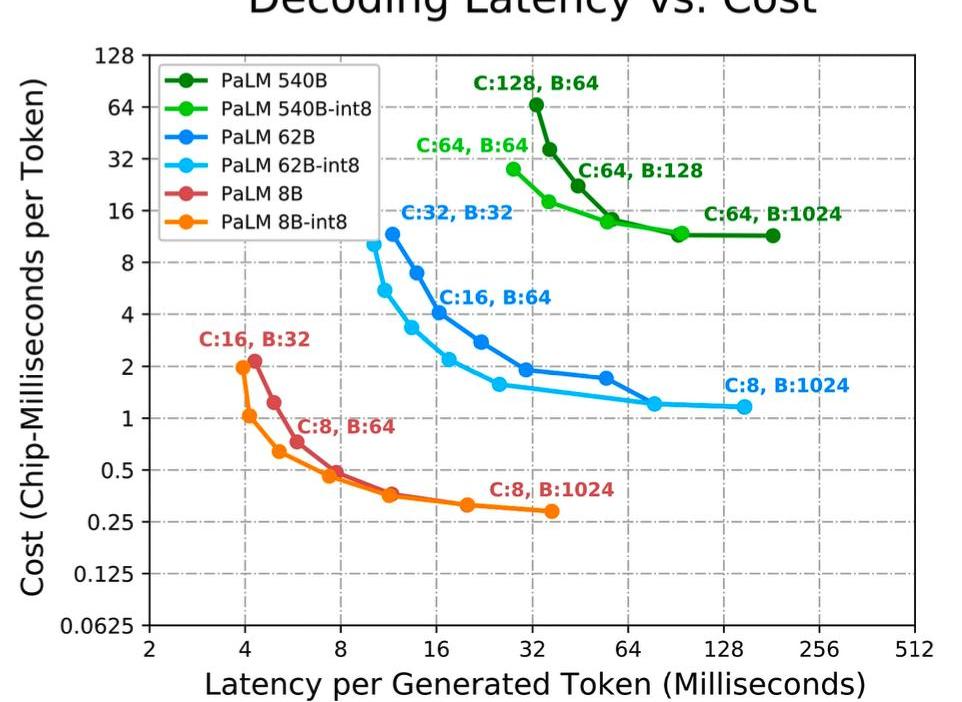
谷歌在他們的PaLM推理論文中展示了這些權衡。然而,值得注意的是,這是針對像PaLM這樣的稠密模型,而不是像GPT-4這樣的稀疏模型。
如果一個應用程序要求最低的延遲,我們需要應用更多的芯片,并將模型劃分為盡可能多的部分。較小的批量大小通常可以實現較低的延遲,但較小的批量大小也會導致更差的利用率,從而導致每個令牌的總成本更高。如果一個應用程序需要離線推理,并且延遲不是問題,主要目標是最大化每個芯片的吞吐量。
增加批量大小是最高效的,因為較大的批量通常可以實現更好的利用率,但某些對于小批量大小來說不高效的劃分策略在批量大小增大時變得高效起來。更多的芯片和更高的批量大小是最便宜的,因為它們可以增加利用率,但這也引入了一個第三個變量,即網絡時間。某些將模型分割到不同芯片上的方法對于延遲更高效,但與利用率相互制衡。
內存時間和非注意計算時間都與模型大小成正比,與芯片數量成反比。然而,對于給定的分區布局,芯片間通信所需的時間下降得較慢,因此隨著芯片數量的增加,它變得越來越重要,成為一個越來越重要的瓶頸。雖然我們今天只是簡單地討論一下,但應該注意到,隨著批量大小和序列長度的增長,KV緩存的內存需求會急劇增加。如果一個應用程序需要生成具有較長注意力上下文的文本,則推理時間會顯著增加。
對于一個具有多頭注意力的500B+模型,注意力KV緩存會變得很大:對于批量大小為512和上下文長度為2048,KV緩存總共達到3TB,這是模型參數大小的3倍。芯片上的內存需要將此KV緩存從芯片外存加載到內存中,而此期間芯片的計算核心基本上處于閑置狀態。較長的序列長度對內存帶寬和內存容量特別不利。OpenAI的16k序列長度GPT3.5turbo和32k序列長度GPT4的成本要高得多,因為由于內存限制,它們無法使用更大的批量大小。
較低的批量大小導致較低的硬件利用率。此外,隨著序列長度的增加,KV緩存也會變得更大。KV緩存無法在用戶之間共享,因此需要單獨的內存讀取,進一步成為內存帶寬的瓶頸。
7GPT-4的推理權衡和基礎設施
以上所有內容在GPT-4推理中都很困難,但是模型架構采用了專家混合模型,這引入了一整套新的困難。每個令牌生成的前向傳遞可以路由到不同的專家集合中。這對于在批量大小較大時在吞吐量、延遲和利用率之間實現的權衡造成了困擾。
OpenAI的GPT-4有16個專家,每個前向傳遞中有2個專家。這意味著如果批量大小為8,每個專家的參數讀取可能只是批量大小為1。更糟糕的是,可能一個專家的批量大小為8,而其他的專家可能是4、1或0。每次令牌生成,路由算法都會將前向傳遞發送到不同的方向,導致令牌到令牌的延遲以及專家批量大小的顯著變化。推理基礎設施是OpenAI選擇較少的專家數量的主要原因之一。如果他們選擇了更多的專家,內存帶寬將更加成為推理的瓶頸。
OpenAI在推理集群上經常達到4k+的批量大小,這意味著即使在專家之間進行了最佳的負載均衡,專家的批量大小也只有約500個。這需要非常大量的使用才能實現。我們了解到,OpenAI在一個由128個GPU組成的集群上運行推理。他們在多個數據中心和地理位置上都有多個這樣的集群。推理是在8路張量并行和16路流水線并行上進行的。每個由8個GPU組成的節點只有大約130B的參數,即每個GPU在FP16模式下不到30GB,在FP8/int8模式下不到15GB。這使得推理可以在40GB的A100芯片上運行,前提是所有批次的KV緩存大小不會過大。
包含各種專家的單個層不會分割到不同的節點上,因為這會使網絡流量過于不規則,并且在每個令牌生成之間重新計算KV緩存的代價太高。對于任何未來的MoE模型擴展和條件路由,如何處理KV緩存的路由是一個最大的困難。
模型有120個層,所以將其平均分配到15個不同的節點上是很簡單的,但由于第一個節點需要進行數據加載和嵌入,所以在推理集群的主節點上放置較少的層是有意義的。此外,我們聽到了一些關于推理的猜測解碼的傳言,我們稍后會討論,但我們不確定是否相信這些傳言。這也可以解釋為什么主節點需要包含較少的層。
8GPT-4的推理成本
與175B參數的Davinchi模型相比,GPT-4的成本是其3倍,盡管其前饋參數只增加了1.6倍。這主要是因為GPT-4需要更大的集群并實現了更低的利用率。
我們認為,對于128個A100來推理GPT-48k序列長度,每1k令牌的成本是0.0049美分,而對于128個H100來推理GPT-48k序列長度,每1k令牌的成本是0.0021美分。
值得注意的是,我們假設有較高的利用率,并保持較高的批量大小。這可能是一個錯誤的假設,因為很明顯OpenAI有時的利用率非常低。我們假設OpenAI在低谷時段關閉集群,并重新調整這些節點以從檢查點恢復對較小測試模型的訓練,嘗試各種新技術。這有助于降低推理成本。如果OpenAI不這樣做,他們的利用率將更低,我們的成本估計將增加一倍以上。
9多查詢注意力
MQA是其他公司正在使用的技術,但我們想指出OpenAI也在使用。長話短說,只需要一個頭部,KV緩存的內存容量可以大大減少。即使如此,32k序列長度的GPT-4肯定無法在40GB的A100芯片上運行,而8k序列長度的GPT-4在最大批量大小上受到限制。如果沒有MQA,8k序列長度的GPT-4的最大批量大小將受到極大的限制,以至于經濟上不可行。
10連續批處理
OpenAI實現了可變的批量大小和連續批處理。這樣可以在一定程度上允許最大延遲,并優化推理成本。如果您對這個概念不熟悉,那么這篇由AnyScale撰寫的文章值得一讀。
11關于猜測解
我們從一些可靠的人士那里聽說OpenAI在GPT-4推理中使用了猜測解碼。我們不確定是否完全相信這一點。令牌到令牌的延遲的普遍變化以及在進行簡單的檢索任務與更復雜的任務時的差異似乎表明這是可能的,但是變量太多,無法確定。以防萬一,我們將在這里使用一些“使用分段猜測解碼加速LLM推理”的文本并稍作修改/添加一些說明。
使用LLM通常分為兩個階段。首先是預填充階段,將提示文本通過模型生成KV緩存和第一個輸出的logits。通常,這個階段很快,因為整個提示文本可以并行處理。
第二階段是解碼。從輸出的logits中選擇一個令牌,并將其反饋到模型中,生成下一個令牌的logits。重復這個過程,直到生成所需數量的令牌。因為解碼必須按順序進行,每次都要將權重流通過計算單元以生成單個令牌,所以當以小批量運行時,第二階段的算術強度非常低。
因此,解碼通常是自回歸生成中最昂貴的部分。這就是為什么在OpenAI的API調用中,輸入令牌比輸出令牌便宜得多的原因。
猜測解碼的基本思想是使用一個更小、更快的草稿模型預先解碼多個令牌,然后將它們作為一個批次饋送給神諭模型。如果草稿模型對其預測的令牌是正確的,即較大模型也同意,那么可以通過一個批次解碼多個令牌,這樣可以節省相當多的內存帶寬和時間,每個令牌都能節省。
然而,如果較大模型拒絕了草稿模型預測的令牌,那么剩下的批次將被丟棄,算法自然會恢復到標準的逐令牌解碼。猜測解碼可能還伴隨著拒絕采樣方案,以從原始分布中進行采樣。請注意,這僅在帶寬是瓶頸的小批量設置中有用。
猜測解碼通過交換計算和帶寬來進行權衡。猜測解碼作為性能優化目標具有兩個關鍵原因。首先,它完全不會降低模型質量。其次,它提供的優勢通常與其他方法無關,因為其性能來自將順序執行轉換為并行執行。
目前的猜測方法為批次預測一個單獨的序列。然而,這在大批量大小或低草稿模型對齊度的情況下無法很好地擴展。直觀地說,兩個模型在連續的長序列中達成一致的概率指數級地降低,這意味著隨著算術強度的擴大,猜測解碼的回報迅速減少。
我們認為如果OpenAI使用猜測解碼,他們可能只在大約4個令牌的序列上使用它。順便提一下,GPT-4降低質量的整個陰謀可能只是因為他們讓神諭模型接受來自猜測解碼模型的較低概率序列。另一個注意的是,有人猜測Bard使用了猜測解碼,因為谷歌在將整個序列發送給用戶之前等待序列的生成完成,但我們不相信這種猜測是真實的。
12關于視覺多模態
視覺多模態能力是GPT-4中最不令人印象深刻的部分,至少與領先的研究相比。當然,還沒有任何公司將多模態LLM的研究商業化。
它是一個獨立的視覺編碼器,與文本編碼器分開,但存在交叉注意力。我們聽說它的架構類似于Flamingo。這在GPT-4的1.8T參數之上增加了更多的參數。在僅文本預訓練之后,它還進行了另外約2萬億個令牌的微調。
對于視覺模型,OpenAI原本希望從頭開始訓練,但這種方法還不夠成熟,因此他們決定先從文本開始以減輕風險。
據稱,下一個模型GPT-5將從頭開始進行視覺訓練,并且能夠自己生成圖像。此外,它還將能夠處理音頻。
這種視覺能力的主要目的之一是讓自主代理能夠閱讀網頁并轉錄圖像和視頻中的內容。他們訓練的數據中有一部分是聯合數據、網頁的屏幕截圖、YouTube視頻:采樣幀,并運行Whisper來獲取轉錄。
關于所有這些針對LLM的過度優化的有趣之處在于,視覺模型的成本與文本模型的成本不同。正如我們在“亞馬遜云危機”文章中所描述的那樣,在文本模型中,成本非常低。而在視覺模型中,數據加載的IO要高出約150倍。每個令牌的字節數為600,而不是文本的4。有很多關于圖像壓縮的研究正在進行中。
這對于那些正在根據未來2-3年內LLM的用例和比率來優化硬件的硬件供應商來說非常重要。他們可能會發現自己處于一個每個模型都具有強大的視覺和音頻能力的世界中。他們可能會發現他們的架構適應不良。總的來說,架構肯定會發展到超越當前簡化的基于文本的密集和/或MoE模型的階段。
數字人民幣新功能正式上線。11日,有安卓手機用戶發現,數字人民幣App已上線SIM卡硬錢包功能.
1900/1/1 0:00:00美聯儲官員釋放加息信號 美東時間周一(10日),美國三大股指全線收漲,道指漲0.62%,納指漲0.18%,標普500指數漲0.24%.
1900/1/1 0:00:00跨境出海20載,風云巨變在今朝。鯨商(ID:bizwhale)原創作者|陶路、蔓聽孩提過去20多年里,跨境電商經歷了莽荒時代的野蠻生長,無論是B2B貿易還是B2C零售,都在PC和移動互聯網的浪潮.
1900/1/1 0:00:00FM-Radio市場概述 非農就業意外放緩未能拯救美股,三大美股指周五三連跌,7月首周“開門黑”.
1900/1/1 0:00:00PiNetwork是一項旨在通過去中心化的區塊鏈技術改變數字貨幣世界的創新項目。而在實現這個目標之前,PiNetwork經歷了一個重要的發展階段——封閉網絡期.
1900/1/1 0:00:00中東與北非陽光充足、風力強勁、又靠近亞洲和歐洲主要市場,非常適合用新能源制備綠氫。經過一番調查,我們才發現,中東北非五國當下對于綠氫的布局,堪稱低調而又宏大,遠遠超出我們想象。氫是二次能源.
1900/1/1 0:00:00


