






 BTC/HKD+0.46%
BTC/HKD+0.46% ETH/HKD-0.15%
ETH/HKD-0.15% LTC/HKD+0.11%
LTC/HKD+0.11% DOT/HKD+0.3%
DOT/HKD+0.3% ADA/HKD-0.3%
ADA/HKD-0.3% SOL/HKD-0.32%
SOL/HKD-0.32% XRP/HKD-0.49%
XRP/HKD-0.49% DOGE/US-0.32%
DOGE/US-0.32%大綱
本篇文章目的是通過具體示例,介紹完整的性能項目過程,具體內容介紹區塊鏈性能測試中使用的:1.基本概念2.常用工具3.性能調優的常見情況這3塊內容涵蓋的內容非常多,每一個內容都有很多書籍和文章介紹,詳細的內容不會出現在本文中。基本概念
區塊鏈的性能測試,方法論上與傳統的性能測試沒有不同。性能測試有很多混亂的概念,這里我列出本文描述概念做一些定義。性能測試的定義
性能測試是對系統或者服務的性能指標建立監控策略,在特定場景下執行測試,分析判斷性能瓶頸并調優,最終得出性能結果來評估系統或者服務的性能指標是否滿足既定值。這里結合cosmos-sdk的simapp區塊鏈來解釋。1.需要明確指標,一般指兩類指標:技術指標、業務指標。技術指標一般是TPS,響應時間,資源利用率,對應到區塊鏈一般是指每秒可以處理多少筆交易?這些交易的響應時間或者統計結果是多少?在這種情況下系統使用的資源處于什么狀態?期望滿足的業務指標,應該來源于生產環境統計,以cosmos-sdk的生產應用cosmos-hub為例,其現階段出塊時間大約6秒,每個區塊中的交易數大多數小于10。期望的業務指標設定為TPS為100是較為合理的。。2.測試模型:是真實場景的抽象,描述業務模型是什么樣的。以cosmos-hub為例大致就是,分布在全球的區塊鏈節點,在驗證者節點約500個,活躍驗證者節點約為200的情況下處理交易。測試時可以按比例抽象實際情況。3.測試方案:包括測試環境,測試數據,測試模型,性能指標等。對比區塊鏈系統的測試,就是確定測試架構,準備好如1000個用戶,每個用戶余額1000stake這樣的內容。4.需要有監控:監控的對象有壓力機、區塊鏈節點、其他如負載均衡服務器等。云原生時代的監控一般是Kubernetes+Prometheus+Grafana。5.需要測試條件:硬件環境,測試執行策略等。例如:4C8G,前60秒,每秒增加10個線程。6.需要有場景:指性能場景,正式化的描述是:在既定的環境、既定的數據、既定的執行策略、既定的監控之下,執行性能腳本,同時觀察系統各層級的性能狀態參數變化,并實時判斷分析場景是否符合預期。性能場景,有時被稱為測試用例其實是不對的。7.要有結果報告:報告內容當然就是實際的指標數據。性能場景分類
中國移動發布2021年可持續發展報告:持續鍛造區塊鏈等核心能力引擎:金色財經報道,中國移動近日發布2021年可持續發展報告,報告指出中國移動將構建“連接+算力+能力”新型信息服務體系,持續鍛造業界領先的區塊鏈等核心能力引擎。[2022/6/18 4:36:17]
1.基準性能場景:做單交易/接口的容量,為混合容量做準備。2.容量性能場景:混合容量測試是因為線上真實場景就是由不同的業務組成的,所以由這些業務按照不同并發比例發起梯度壓測就是混合容量測試場景。3.穩定性性能場景:核心就是時長,在長時間的運行之下,觀察系統的性能表現。這個時長的設置,應該來源于運維周期。4.異常性能場景:在強壓力之下,模擬異常。重要的性能指標
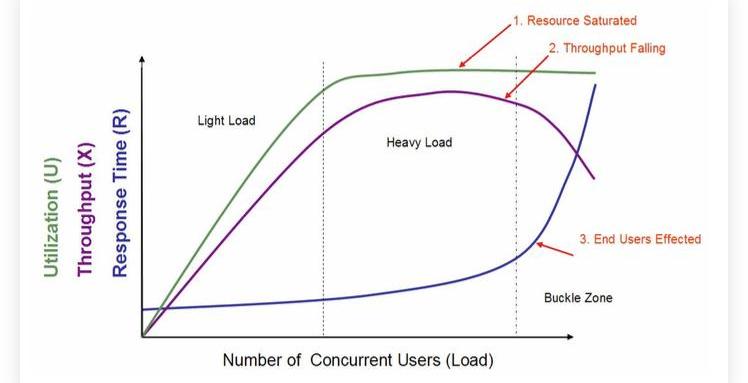
性能測試的指標有很多,比如:1.RT,ResponseTime2.HPS,HitsPerSecond3.TPS,TransactionsPerSecond,這里的Transactions在傳統的應用中一般稱為”事務“,在區塊鏈領域指”交易“4.QPS,QueriesPerSecond5.PV,PageView6.Throughput7.IOPS,Input/OutputOperationsPerSecond比較重要的指標有資源使用率、吞吐量、響應時間,服務提供方比較關心前兩者,用戶更更新后者。關于這些指標的一般情況引用PerformanceTestingMethodology(http://hosteddocs.ittoolbox.com/questnolg22106java.pdf)中的經典圖來說明,實際情況可能不同。圖中定義了3線3區域3狀態,這個圖值得多看看,能夠大致理解指標簡的關系。1.3線:Utilization,Throughput,ResponseTime2.3區域:LightLoad,HeavyLoad,BuckleZone3.3狀態:ResourceSaturated,ThroughputFalling,EndUsersEffected
視覺中國:公司元視覺平臺依托區塊鏈技術生成唯一數字憑證:金色財經消息,視覺中國(000681.SZ)4月13日在投資者互動平臺表示,公司元視覺平臺依托區塊鏈技術生成唯一數字憑證,幫助藝術家創作的特定藝術作品實現不可分拆、不可復制、不可篡改。在保護其數字版權的基礎上,實現真實可信的數字與實體藝術品的發行、收藏和使用,幫助藝術家、優質IP提升藝術作品的變現能力。(每日經濟新聞)[2022/4/13 14:22:40]
其他
1.一般需要在什么時候做性能測試。a.項目上線前,估計系統承載能力b.項目重構后,評估效果2.如果一個項目得到性能報告就終止,這樣就只是性能驗證。做完全面的性能測試,同時將系統調優到最優狀態,才算是一個完整的性能項目了。性能調優耗時長,還可能需要開發參與,代價高。區塊鏈性能測試區塊鏈的性能測試的指標最重要的是TPS與延遲,a16z的文章Whyblockchainperformanceishardtomeasure對此做了很有洞察的討論,說明了為什么這兩個指標很難測量和比較。其主要內容有以下方面:延遲
聲音 | 長沙晚報:積極運用區塊鏈助力國家治理現代化:《長沙晚報》今日發表題為“積極運用區塊鏈助力國家治理現代化”的評論文章。文章指出,在中央局第十八次集中學習中,習近平總書記強調區塊鏈技術的集成應用,區塊鏈被提升到國家戰略層面。區塊鏈在促進數據共享、優化業務流程、降低運營成本、提升協同效率、建設可信體系等方面的重要作用啟示我們,區塊鏈不僅要作為核心技術自主創新的重要突破口,還要作為推進國家治理現代化的重要依托。文章最后還表示,我們也要清醒地認識到,區塊鏈技術發展尚處于早期階段,應用還不成熟,運行安全面臨挑戰,可能給國家安全、意識形態安全、主權安全、金融安全等帶來諸多風險。因此,既要作為產業藍海來提前布局,又要合理規避其中的可能風險,強化頂層設計,完善機制建設,夯實底板,補足短板,推動區塊鏈健康發展,使之成為助力國家治理現代化的有效手段。[2019/10/31]
延遲的這段時間的起點和終點如何定義?1.起點是用戶點擊提交還是交易到達內存池?2.終點是交易被第1個區塊確認?還是被第6個區塊確認?又或者是最終用戶收到接口響應的時間?3.有些區塊鏈系統對交易會等待一定延遲和到達一定數量才開始處理。這樣比較幸運的就是最后加入的交易,其處理延遲最短。4.對于上訴問題的一種折中方案是,即準確評估整個系統需要考慮延時的分布,而不是將其延遲看做單一數字。5.有些區塊鏈系統的交易處理是有優先級的,fee高的交易很快確認,fee低的相對慢些。fee的不同對交易的延時和TPS的統計是有影響的。吞吐量
金色財經現場報道 BitTemple助力全球區塊鏈項目落地新加坡:5月3日晚,世界區塊鏈中心·BitTemple新加坡開幕酒會上,來自科技寺負責人趙曌上臺進行演講,在現場記者了解到,BitTemple是一個落地于新加坡的專門為區塊鏈領域創業者提供辦公空間、資源支持和項目孵化的區塊鏈孵化器,位于新加坡市中心的最高大樓Republic Plaza,共提供300工位助力全球區塊鏈項目落地新加坡。[2018/5/3]
區塊鏈中的吞吐量,即TPS(TransactionPerSecond)來衡量,這里的transaction顯示不是平等的,最簡單的例子就是以太坊中的交易,它可以是轉賬也可以是調用合約。因此,得出TPS需要指定T指代的是什么。另外一個實際的問題是,用戶其實不關心一個區塊鏈的TPS是多少,用戶只關心如何少用fee并盡快完成交易。從這個角度來講,TPS只對系統服務提供商有意義。基本工具
壓力工具
壓力工具一般用Jmeter或者特定應用專用測試工具如下:1.hyperbench/hyperbench2.hyperledger/caliper:Ablockchainbenchmarkframeworktomeasureperformanceofmultipleblockchainsolutions3.https://github.com/xuperchain/xbench4.…使用Jmeter應該是更貼近使用場景,更通用。一般與區塊鏈節點進行交互的方式有1.gRPC協議2.HTTP協議(REST接口)Jmeter支持的Sampler支持有HTTP,對gRPC協議的支持需要借助插件jmeter-grpc-request監控工具
IBM CEO:至少有53個IBM客戶正運行400多個區塊鏈項目:IBM首席執行官Ginni Rometty近日表示,至少有53位IBM客戶正在運行400多個區塊鏈項目。這些客戶中有25家全球貿易公司,14家食品追蹤公司,以及14家全球支付公司。一些IBM最知名的區塊鏈客戶包括雀巢、Visa、沃爾瑪、聯合利華和匯豐銀行。[2018/3/9]
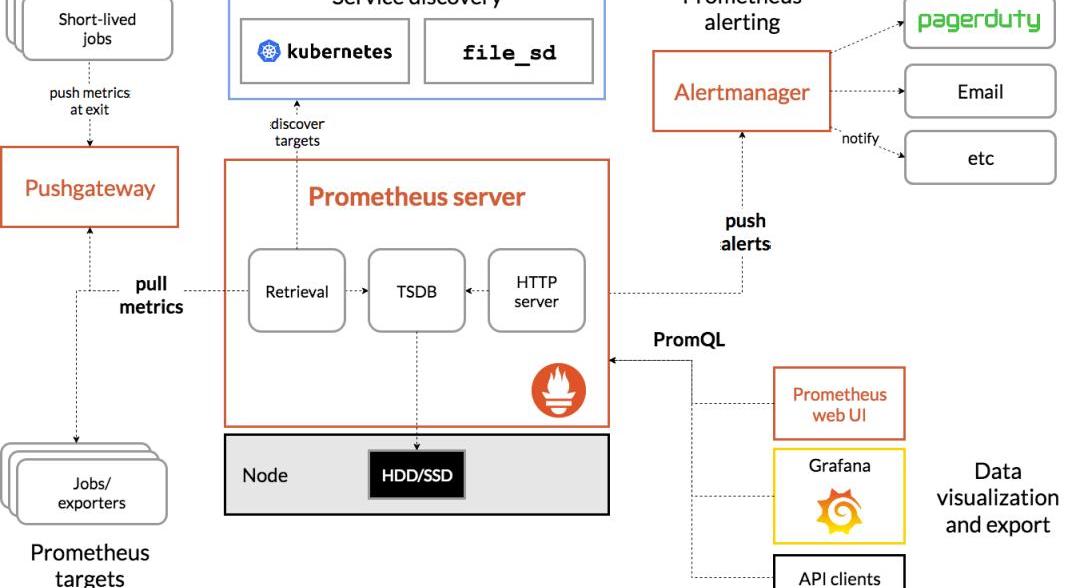
監控工具一般用Prometheus這工具可以監控的內容比較多,其生態如圖(https://prometheus.io/assets/architecture.png)。在測試區塊鏈應用的實踐中,一般是先使用docker-compose部署多個區塊鏈節點模擬正式進行測試的環境,因為正式的測試環境一般硬件配置較高,如果不是自建機房,使用云服務廠商的機器,費用昂貴,這樣做可以節約成本。docker-compose中可以限制容器使用的資源,如內存和CPU算力,甚至綁定CPU核心,對這些資源的監控可以使用cadvisor。為了驗證CPU限制是否準確,可以用stress-ng壓滿核心,看統計結果是否與限制值一致。
性能調優
一般遇到性能瓶頸的常見元原因會是網絡、CPU、磁盤IO。引發磁盤IO的瓶頸的操作有寫日志頻頻繁,打印不必要的日志,通過網絡訪問磁盤等。這些資源都會通過系統調用來完成,跟蹤系統調用,可以使用strace來查看執行了哪些系統調用,以及在這些調用上花費的時間等信息還可能遇到的問題是系統不穩定,可以表現為CPU使用率/TPS不穩定。如果在LightLoad區域選擇一定的并發壓力,TPS波動較大的話,可能就是系統設計得不好,需要找到原因和優化了。如果是CPU使用率不穩定,從CPU指令執行層面來看為CPU處于idle狀態的時長參差不齊。這種情況下的原因并不在于有CPU有idle,而是在于處于idle的時間段有長有短。需要借助Linux系統工具、程序對應的profilling工具來觀測,找到原因。分析工具
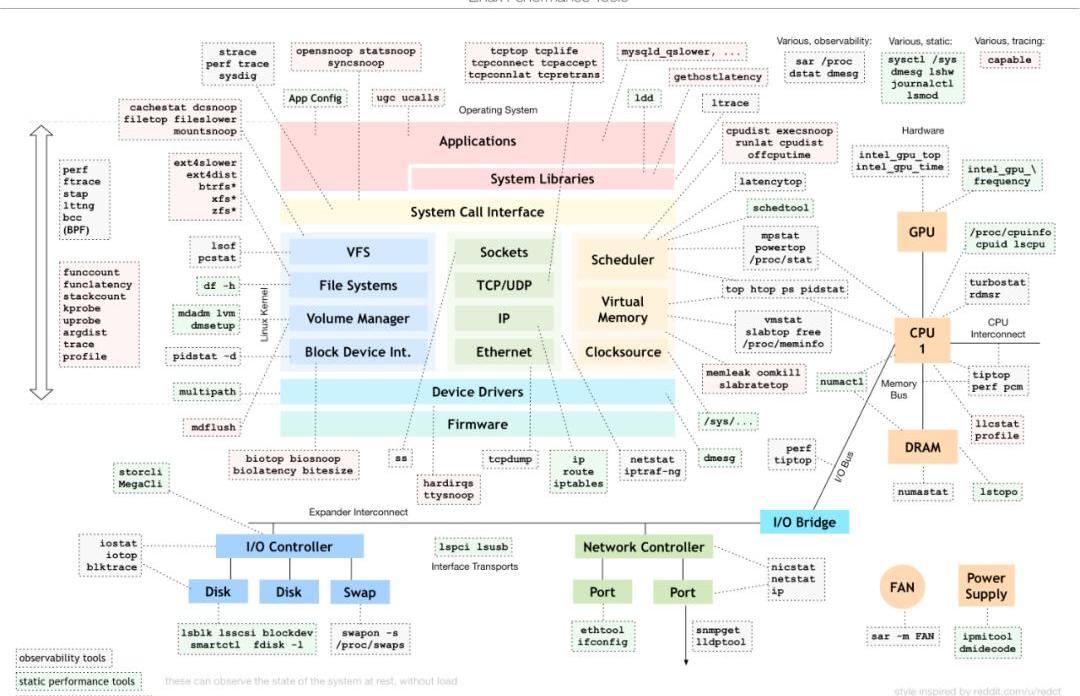
要解決性能問題,首先需要找到原因,尋找原因的分析工具可以參考下圖(https://www.brendangregg.com/Perf/linux_perf_tools_full.png)。這是Linux性能分析最重要的參考資料了,顯示了在不同子系統出現性能問題后,應該用什么樣的工具來觀測和分析。
磁盤IO
磁盤IO一般會導致系統瓶頸,磁盤IO棧比較長,分析起來難度不小。熟悉IO棧,有助于我們發現問題(https://www.thomas-krenn.com/en/wikiEN/images/c/c2/Linux-storage-stack-diagram_v6.2.pdf)
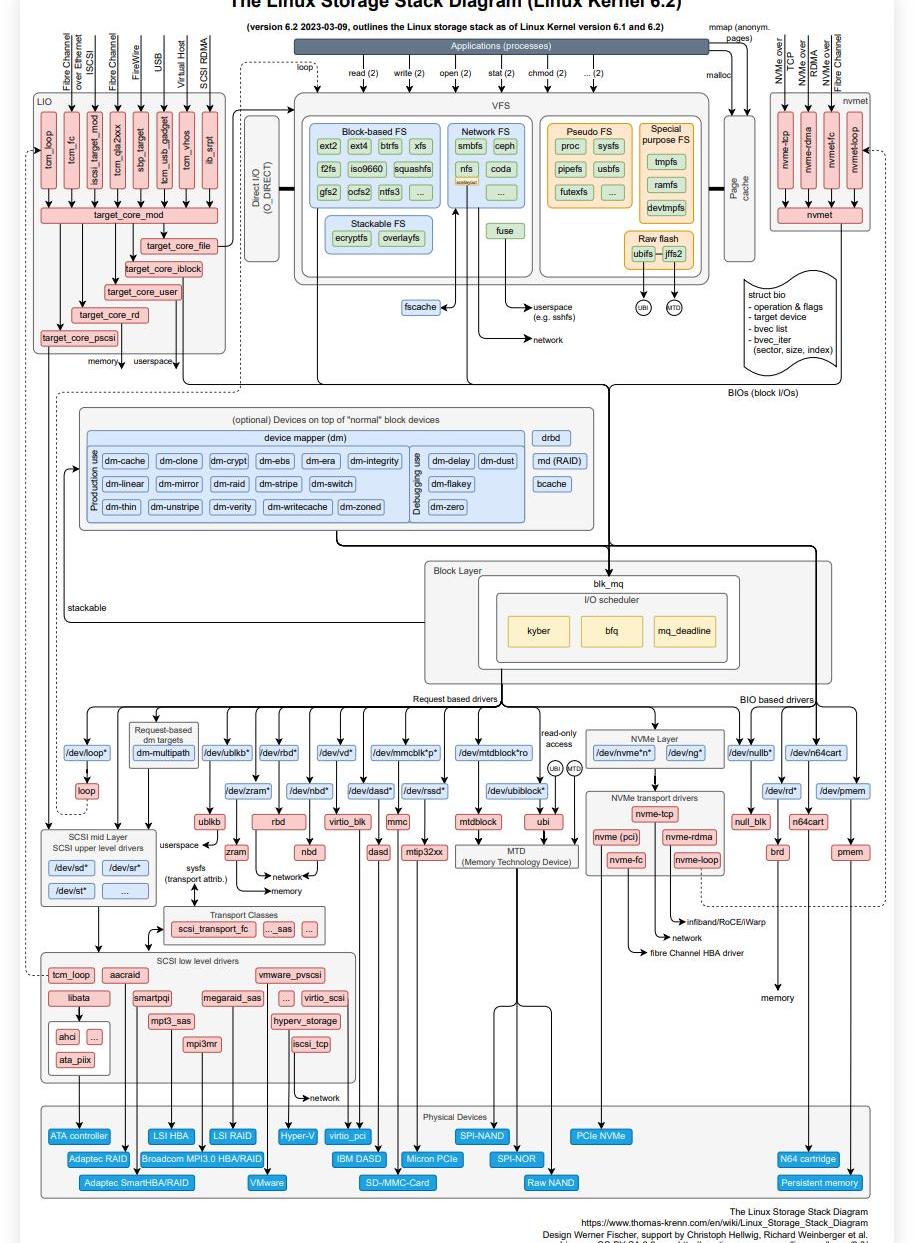
找到原因后,如果能夠通過調整操作系統參數或者應用系統參數優化性能是比較快捷的,如果需要修改代碼,則會涉及系統架構優化,會有涉及和編碼工作,調優周期會很長。下一篇文章將分享使用cosmos-sdk中的SimApp來進行性能測試以及在性能調優方面的方法。
Tags:區塊鏈TPSMETCPU區塊鏈的未來發展前景作者是誰https://etherscan.ioMetaPirateAiCPU幣
3月14日,dYdX社區投票通過DIP-20提案,決定將交易獎勵減少45%,剩余的55%獎勵將由國庫留存,并可經由社區投票改做他用,其中贊成票比例為83%.
1900/1/1 0:00:00Host:MuyiGuest:RobertHu,SSVNetwork中國大使“SSV就是基于DVT技術的去中心化驗證器基礎設施.
1900/1/1 0:00:00在上周周末,所有人都被硅谷銀行事件吸引了眼球,但比特幣NFT社區卻好像在另一個加密世界,分享自己穿著巫師服裝洗澡的照片和視頻,熱絡的玩著社區的游戲.
1900/1/1 0:00:00你是否因錯過了Arbitrum空投而感到惋惜?上周,$ARB空投獲得者平均賺了2350美元。像$ARB、$OP和$APT這樣的空投讓很多空投獵人成為了百萬富翁.
1900/1/1 0:00:00上周末,市場因美國銀行界可能發生的系統性危機而受到沖擊。伴隨硅谷銀行正式破產,其客戶之一Circle的USDC部分質押品存在損失可能,隨之USDC脫鉤.
1900/1/1 0:00:00最近一周,部分山寨匯率開始走高,市場對于新項目的參與熱情持續上升。本周,Odaily星球日報甄選了近期即將在多個平臺首發的8項目名單,并分別做簡要介紹.
1900/1/1 0:00:00


